如何迁移传统 Hive 到新一代极速云数仓 OushuDB
现在,各大企业在hive中存储的数据量越来越多,业务场景越来越复杂,hive的性能也更难以满足企业的要求,只能通过扩展服务器的方式来提升hive的性能,随之而来的是硬件成本和运维成本的增加。因此各大企业也在逐步寻找替代hive的产品,性能和迁移成本是比较受关注的点。
OushuDB作为一款高性能云数仓,支持访问标准的ORC文件,并且具备高可扩展,遵循ANSI-SQL标准,具有极速执行器,提供PB级数据交互式查询能力,可以作为替换hive的首选产品。OushuDB不仅解决了大数据量下计算性能的问题,同时兼容标准ORC格式文件并且语法遵循ANSI-SQL标准为快速迁移提供了技术上的支持。
下面我们就来介绍一下hive数据迁移到OushuDB的方法。
01数据迁移至 OushuDB 的方法
数据迁移有两种方法:全量整体迁移和业务模块分批次迁移,此次采用的方法是全量整体迁移。
1.1.全量整体迁移
整体批量迁移的方式是通过一些批量脚本在hive中卸载数据、抽取到OushuDB中,然后直接在OushuDB中装载到对应的目标库中,等待数据装载完毕,OushuDB中的新系统即可以开始启动相应的跑批程序进行并行跑批。

全量整体迁移示例图
批量转换方式的基础是迁移前后类型的一致,需要批量对建表语句进行转换,生成OushuDB中的加载外表DDL和实际应用表的DDL。
1.2.业务模块分批次迁移
业务模块分批次迁移的方式是通过对hive中的各个业务系统进行详细的拆分,划分出各类业务的范围,然后通过开发人员在OushuDB中进行逐个迁移,各个业务的数据迁移形式如同全量整体迁移一样迁移单个业务的数据。
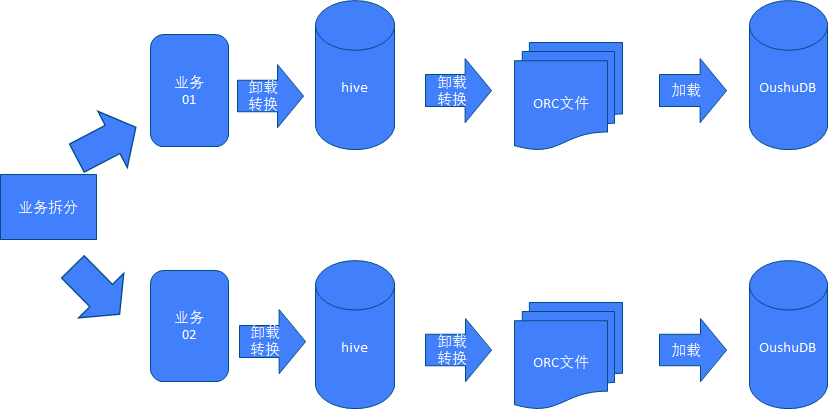
业务模块分批次迁移示例图
业务模块分批次迁移适用于数据量特别大的hive系统,即单次迁移的时间窗口或者服务器容量不满足hive和OushuDB并行的情况。
1.3迁移方式对比
全量整体迁移和业务模块分批次迁移各自的优缺点如下:
全量整体迁移,快速一次性的进行迁移,对业务人员的依赖程度低,但是需要有足够迁移的时间窗口和足够多的空闲服务器供迁移系统使用。
业务模块分批次迁移,少量多次进行迁移,对业务人员依赖程度高,单次迁移时间窗口小,不需要太多的空闲机器,可以逐步下架hive服务器供OushuDB使用。
02数据分类原则
迁移前需要对hive中的数据进行分析分类:
A、类数据表示hive中的不需要迁移的数据
B、类数据表示hive中需要迁移的数据
C、类数据表示可以直接可以在OushuDB中进行铺底和补录的数据
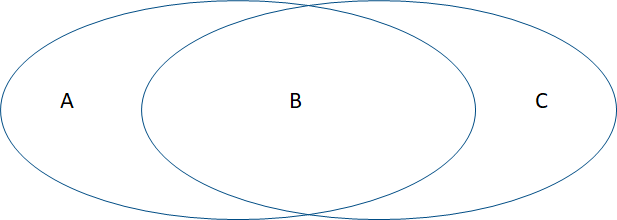
数据分类示意图
由于不同企业对生产系统的管理标准不一致,导致生产系统中可能存在垃圾表和测试表的存在,全部将这些表进行迁移会导致迁移的时间窗口变长且增大迁移的工作量,这个时候需要对生产系统中的存量表进行梳理,梳理出一份存量表清单,对存量的表进行标注筛选出需要迁移的数据表以及存量表的存储方式和存量数据的大小,为后续迁移脚本和迁移策略提供帮助。
03数据迁移原则
数据迁移需要保证如下原则:
1)及时性,由于数据从hive迁移到OushuDB时需要占用操作系统资源,为了保证不影响当日批次必须在给定的时间窗口内完成迁移
2)准确性,数据从hive中迁移到OushuDB之后需要保证数据的准确性,确保迁移后的数据记录条数和业务指标与hive中一致
3)完整性,数据迁移的同时需要考虑到周边对接的业务系统的迁移,确保迁移后对周边业务系统无影响不能存在遗漏的情况
4)安全性,迁移程序不能影响hive原有的跑批程序,要保证迁移过程中hive系统的正常运行
5)保密性,企业的数据是机密数据,在迁移的过程中要保证数据的安全防止泄露和被窃取,尽量减少数据文本落地的情况
6)可回退性,必须保证迁移切换过程中的操作是可回退的,一但迁移时间窗口不够或者迁移失败进行快速回退
04数据迁移规则
4.1DDL改造规则
DDL改造规则是为了将hive中需要迁移的数据迁移至OushuDB而制订的一系列数据项迁移转换规则,使其迁移后可以正确无误的录入OushuDB中,符合OushDB中数据的存储规则,以下为典型的几种字段类型处理方式:
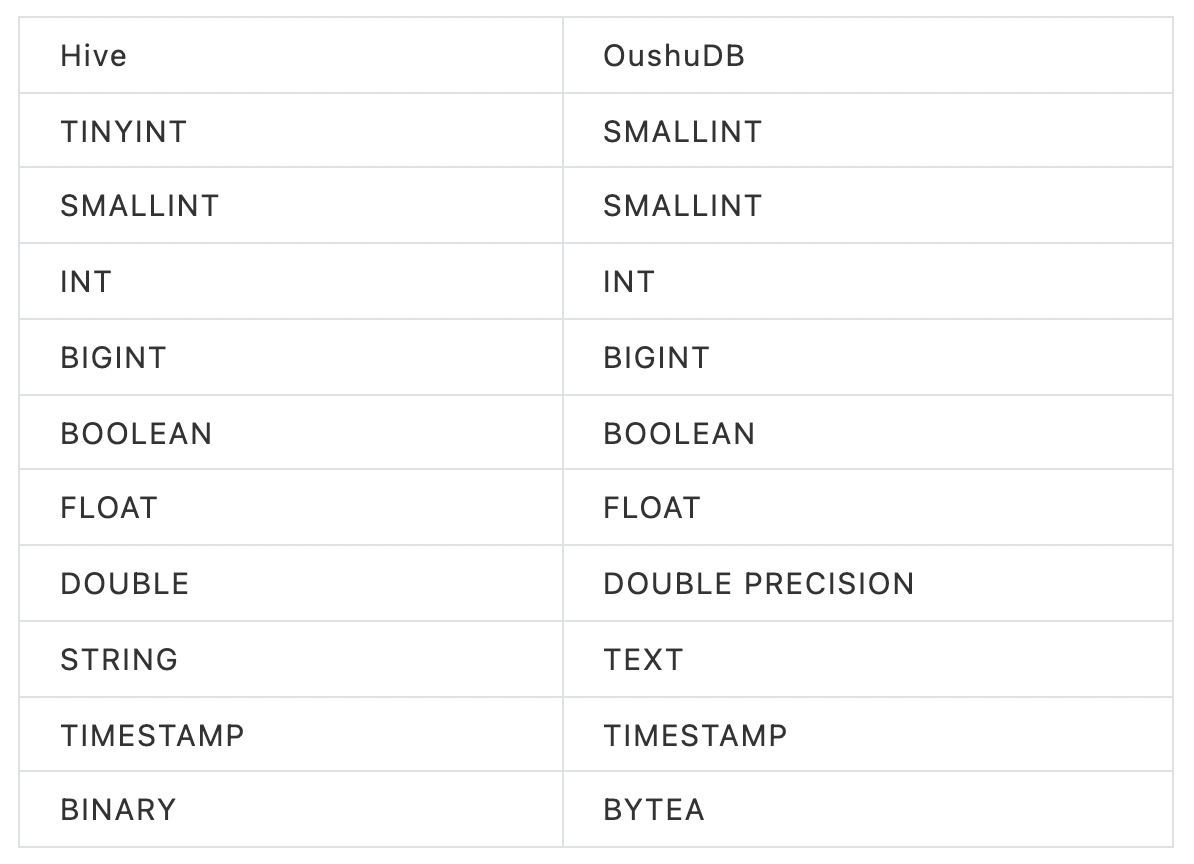
另外建表时OushuDB建表如下所示,创建的表为ORC类型的表,需要将hive中的符合迁移规则的表转换为如下形式:
create table create_table_demo(
col01 int
,col02 SMALLINT
,col03 INT
,col04 BIGINT
,col05 varchar(10)
,col06 decimal(10,2)
,col07 double precision
,col08 text
,col09 TIMESTAMP
);
COMMENT ON TABLE create_table_demo IS 'A table for demo';
COMMENT ON COLUMN create_table_demo.col01 IS 'col01 for demo_table';
COMMENT ON COLUMN create_table_demo.col02 IS 'col02 for demo_table';
COMMENT ON COLUMN create_table_demo.col03 IS 'col03 for demo_table';
COMMENT ON COLUMN create_table_demo.col04 IS 'col04 for demo_table';
COMMENT ON COLUMN create_table_demo.col05 IS 'col05 for demo_table';
COMMENT ON COLUMN create_table_demo.col06 IS 'col06 for demo_table';
COMMENT ON COLUMN create_table_demo.col07 IS 'col07 for demo_table';
COMMENT ON COLUMN create_table_demo.col08 IS 'col08 for demo_table';
COMMENT ON COLUMN create_table_demo.col09 IS 'col09 for demo_table';
4.2数据迁移例外规则
数据迁移例外规则是对数据迁移时发现一些不能用常规方式迁移的表进行筛选出来,开发独立的脚本对这类数据进行迁移,例如hive中的各种外表,各类映射表以及数据量超大的表(几百TB)等,都需要针对不同的表进行独立的迁移脚本开发。
4.3数据迁移各类参数映射规则
由于hive和OushuDB的连接串、各类配置参数存在差异,在迁移过程中需要制订参数的映射规则,确保迁移后业务系统、跑批脚本、上下游程序对OushuDB可以正常对接,可以正常执行完整的业务流程。
05数据迁移验证
生产上的数据不能有一丝一毫的差错,迁移以后结果的验证是非常重要的,可以采用自动核对、报表核对、业务系统验证等手段进行验证。
5.1自动核对
客户信息系统的客户、账户数据量非常大,对数据迁移结果进行明细核对是无法通过人工的形式进行的,只能通过自动化脚本进行核对和人工抽样检查的形式进行明细核对工作,自动化脚本对hive和OushuDB中的数据在并行跑批阶段进行每日自动核对。
5.2报表核对
报表核对是在迁移过程中进行,对迁移成功的时候以及并行跑批阶段的数据按照业务的统计维度对hive和OushuDB中的数据进行核对,确保产生的数据是一致的。
5.3业务系统验证
通过前端的业务系统对hive和OushuDB中的数据进行业务使用场景的查询,对比迁移数据的正确性,并通过一些验证操作对OushuDB进行操作,检查结果是否符合业务系统要求。
06数据迁移工作提示
为了降低数据迁移投产的影响,在数据迁移前的分析阶段需要识别出所有会涉及到的业务系统和需要迁移的数据,落实具体的负责人。制订对应的参数映射规则,业务系统验证流程以及提前准备好需要补录的数据。同时针对不同的企业,需要根据企业内部的特点,制订出合理的数据迁移方案。

