一位金融大数据工程师的HAWQ使用笔记 | HAWQ实战系列
我们一直希望为大家带来一手又接地气的技术干货,在分享一些原创内容的同时,也欢迎大家投稿。作为HAWQ实战系列的开篇,本次我们邀请了一位在金融领域应用HAWQ颇有心得的工程师和大家聊聊一些使用技巧。
作者简介:
阿超,34岁,计算机科班出身,现供职于创维集团。之前将HAWQ成功部署在曾经任职的金融科技公司。借助HAWQ内部表强大的性能优势,将性能提升了4-50倍,达到秒级查询。
以下内容为他在金融科技公司部署HAWQ时的一些经验:
“我之前做过运维,做过DBA,做过部门管理,但是最让我着迷的还是数据仓库工作,之前从事的关系型数据仓库大都基于ORACLE和MYSQL来开发,但是在海量数据面前就有点力不从心了。
大数据生态里用的最多的还是HIVE,但是性能依旧是最头疼的问题,在工作期间也用过Impala和Spark SQL,Spark SQL主要还是内存消耗过大,经常报错,Impala速度很快,但是功能确实欠缺。
第一次知道HAWQ是在2017年夏天,当时我就职于北京一家金融科技公司,主要做企业间的供应链金融业务,朋友向我推荐了HAWQ作为大数据平台下的数据仓库工具,从此开启了我的HAWQ学习和实践之旅。
言归正传,切入主题!”
项目背景
作为金融科技公司,公司的主营业务是金融领域的保理业务,主要做融资放款,历史数据量大概在200T左右,数据仓库的数据源主要由三部分组成,自身业务平台数据+合作客户历史数据+第三方渠道数据,数据仓库主要服务于公司风控团队和量化分析团队。
原有架构

优化架构
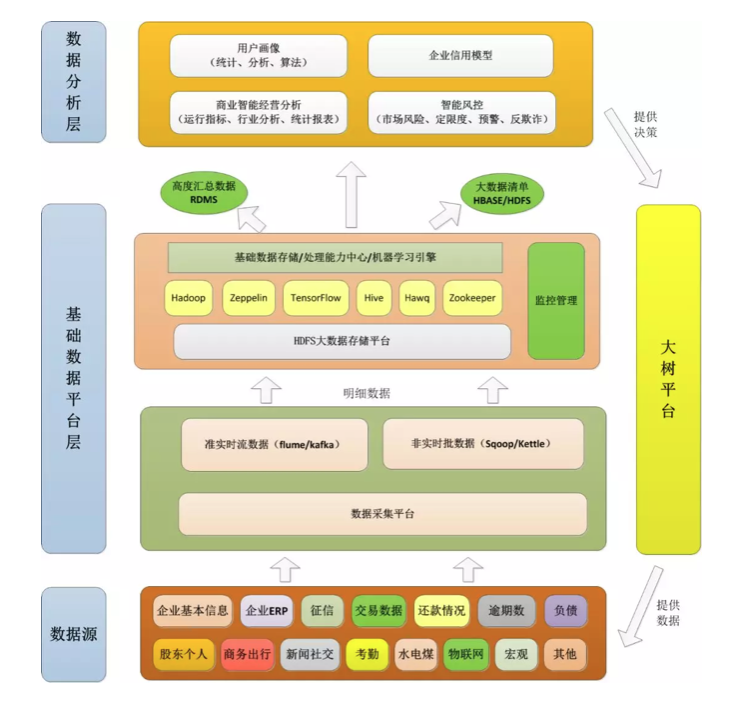
HAWQ在项目中的应用
公司环境:
Linux:CentOS release 6.4,核心2.6.32-358.el6.x86_64
Ambari:2.4.1
Hadoop:HDP 2.5.0
HAWQ:2.1.1.0
MySQL 5.6.14
1.数据源整合和数据装载
原公司存在多种数据源,主要有结构化数据和半结构数据组成,HAWQ在数据源整合方面能力出众,主要通过pxf协议和gpfdist两种方式进行数据装载,我们的做法是先把文本数据(txt/csv)上传至服务器本地或HDFS上,再使用HAWQ外部表用相关协议去读取不同存储位置的文件,并进行了文件分隔符处理和转义标识。
对于较小的文件推荐使用copy命令可直接加载至内部表,对于较大的文件,我们的处理方式通常会采用启动多个gpfdist进程的方式进行数据加载,也会使用pxf加载HDFS上的数据。
对于重复性加载的需求,我们也使用了HAWQ官方推荐的通过一个格式为YAML的控制文件实现数据加载。
2.数仓分层查询
数据仓库各个分层对应HAWQ里就是不同的schema,因为HAWQ本身不支持跨库查询,故建议把所有数据放入一个数据库中,以不同的模式来区分数据层次是合理的;
贴源层
使用HAWQ外部表,直接读取外部数据,不做任何ETL处理;
数据明细层
使用HAWQ内部分区表,parquet存储格式,主要做数据去重、数据规范化处理、逻辑校验等基础ETL工作。
我们在数据明细层之外还添加了一个数据增量模式,主要用于存储增量数据。
维度层
使用HAWQ内部分区表,parquet存储格式,根据我们业务自身的主题,确定相关维度和事实,同时在维度表和事实表中采用拉链处理(缓慢变化维),拉链表主要包含几个核心要素,分别是代理键,业务主键,数据生效日期,数据失效日期,是否最新数据标识。
我们在维度层没有采用王雪迎大哥系列文章里的视图技术,原因在于视图在数据查询时确实速度较慢,虽然在处理迟到事实时有一定优势,但碍于查询速度还是没有采用。
宽表层
宽表层的数据主要来源于维度层,个别数据也会来源于明细层,采用HAWQ内部表存储。HAWQ目前支持最大1200多列,符合公司业务需求。在上亿数据关联查询中,HAWQ内部分区表基本都能控制在秒级,单表查询速度更理想。用户体验优异,频频夸好!
3.数据迁移
我们在实际项目工作中涉及到一次大数据平台数据迁移的需求,我们主要采用了HAWQ可写外部表和可读外部表两种进行了数据迁移操作,具体脚本可参考如下方式:
1、迁移元数据
pg_dump --schema-only -f dwinvoice.schema dwinvoice
scp dwinvoice.schema gpadmin@10.0.54.60:/home/gpadmin
psql -f dwinvoice.schema -d dwinvoice
2、迁移业务数据
--启动进程
gpfdist -d /home/gpadmin/ewdata/ -p 8081 &
--创建可写外部表
create writable external table wext_ea_bj_yjys_debit (like ea_bj_yjys_debit)
location ('gpfdist://10.0.54.60:8081/ea_bj_yjys_debit.csv')
format 'csv';
--数据导出
begin;
insert into wext_ea_bj_yjys_debit select * from rds.ea_bj_yjys_debit;
commit;
--数据转递
scp ea_bj_yjys_debit.csv gpadmin@10.0.54.60:/home/gpadmin
--创建可读外部表
create external table rext_ea_bj_yjys_debit (like ea_bj_yjys_debit)
location('gpfdist://10.0.54.60:8081/ea_bj_yjys_debit.csv') format 'csv';
--导入数据
insert into rds.ea_bj_yjys_debit select * from rext_ea_bj_yjys_debit;
analyze rds.ea_bj_yjys_debit ;
从2017年的初识HAWQ,到现在在企业中推广,整体来说HAWQ在性能上表现卓越,HAWQ内部表比Hive on Tez快的大约4-50倍。在我们实际项目案例中千万级的单表查询时间基本可以控制在5秒左右,多表关联查询时间也比原有Spark SQL要快20倍左右。相信HAWQ在中国的发展会越来越好,一起为国人开发的数据查询引擎点赞!

