逝世五年——你必须认识的这位数据库之父
五年前,也就是 2017 年 7 月 13 日,“数据库之父”查尔斯·巴赫曼 (Charles Bachman) 逝世。

上学时,我们的很多课本上都提到了三层体系结构、数据库管理系统概念、DDL、DML 等等这些概念,但都没提到这些概念背后的创造者——查尔斯·巴赫曼。
作为网状数据库之父、DBTG (Data Base Task Group) 之父,查尔斯·巴赫曼的两项重大贡献包括:
1、开发了最早的网状数据库管理系统 IDS (Integrated Data Store)。IDS 于 1964 年推出后,成为最受欢迎的数据库产品之一,它的设计思想和实现技术被后来的许多数据库产品仿效。
2、巴赫曼促成了数据库标准的制定。在美国数据系统语言委员会下属的数据库任务组 DBTG 期间,他提出了网状数据库模型以及数据定义 (DDL) 和数据操纵语言 (DML) 规范说明,并于 1971 年推出了第一个正式报告——DBTG 报告,该报告首次提出了数据库三层体系结构,明确了 DBA 概念,规定了 DBA 的作用与地位,使其成为了数据库历史上具里程碑意义的文献。巴赫曼还发明了一种描述网状数据库模型的数据结构图,被世人称为“巴赫曼图”(Bachman Diagram)。
此外,在担任 ISO / TC97 / SC16 会议主席时,巴赫曼还主持制定了著名的“开放系统互连”标准,即 OSI (Open System Interconection),OSI 对计算机、终端设备、人员、进程、网络之间的数据交换提供了标准,对系统之间互相开放有重要意义。
1973 年,凭借对数据库技术领域的杰出贡献,巴赫曼被授予计算机领域的最高奖项——图灵奖,也是数据库技术领域最早获得图灵奖的先驱。
巴赫曼的"网状数据库"及其发展
查尔斯·巴赫曼研发的网状数据库 (Network Database) 是一种采用网状模型的数据库。网状模型用网状结构表示各类实体及其间的联系。在网状结构中:允许一个以上的结点没有双亲;一个结点可以有多于一个的双亲。网状模型是一种比层次模型更具普遍性的结构,它去掉了层次模型的限制,允许多个结点没有双亲结点,允许结点有多个双亲结点,此外它还允许两个结点之间有多种联系(即复合联系)。因此网状数据模型可以更直接地去描述现实世界。
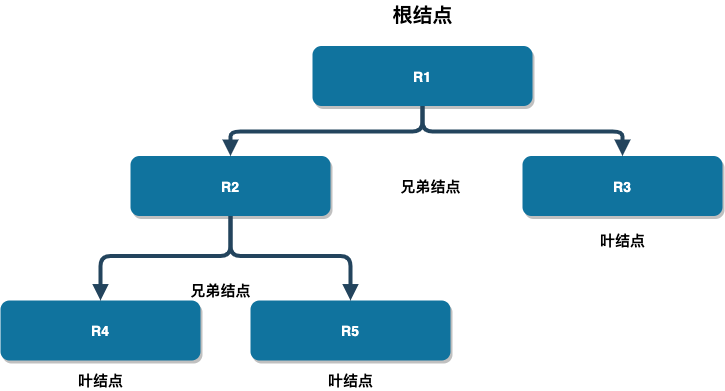
当然,网状数据库也存在一些局限:首先,用户查询和定位在复杂的网状结构中比较难进行;其次,网状数据的操作命令具有过程式的性质;最后,网状数据库的表达并不直接。
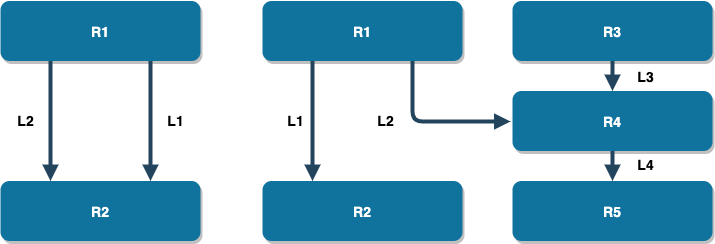
紧随网状数据库后出现的是层次数据库,其数据模型是层次数据模型,即使用树形结构来描述实体及其之间关系的数据模型。在这种结构中,每一个记录类型都用节点表示,记录类型之间的联系则用节点之间的有向线段来表示。每一个子节点只能有一个父节点,但是每一个父节点可以有多个子节点。这种结构决定了采用层次数据模型作为数据组织方式的层次数据库系统只能处理一对多的实体联系。1968 年,世界上第一个层次数据库——信息管理系统 IMS (Information Management System) 诞生于 IBM,也是世界上第一个大型商用的数据库系统。
再后来,就是一直沿用至今的关系型数据库。1976 年,霍尼韦尔公司发布了世界上第一个商用关系型数据库 Multics Relational Data Store。由于关系数据库具有严格的数学理论基础,抽象级别比较高,简单清晰,便于理解使用,用户能够有逻辑的、抽象的处理数据而不必关心数据在计算机中的物理表示和存储,因此关系型数据库得到了迅速发展并成为主流的数据库模型。紧随其后,1979 年诞生了 Oracle,1985 年 IBM 发布了 DB2,1989 年微软发布了 SQL Server,关系型数据库的队伍不断壮大。
当今数据库的应用需求和分类
数据库的应用类型分为 OLTP (Online Transaction Processing,联机事务处理)和 OLAP(Online Analysis Processing,联机分析处理)两种。

OLTP 是传统关系型数据库的主要应用,主要面向基本的、日常的事务处理,例如在线交易。它可以立即将客户端的原始数据传送到计算中心进行处理,并且在短时间内给出处理结果。衡量 OLTP 系统的一个重要指标是系统性能,具体体现为实时响应时间(Response Time),即从用户输入数据到对该请求做出响应的时间。
OLAP 是数据仓库系统的主要应用,OLAP 专门用于支持复杂的分析查询,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观易懂的形式将查询结果提供给决策者。
大数据时代的数据库热潮
随着当今互联网以及物联网等技术的不断发展,各种应用催生大量数据,也促进数据管理工具飞速发展。数据湖、数据仓库、湖仓一体等概念也逐渐产生。在分析型数据库 (OLAP) 领域,曾先后出现 MPP 和 Hadoop,MPP 数据库主要用作数据仓库,Hadoop 大数据平台承担起数据湖的职能。
数据仓库是独立于业务数据库之外的一套数据存储体系,与传统数据库需要直接处理线上业务不同,数据仓库侧重于分析决策,提供直观的数据查询结果。
数据湖早期一般托管在 Hadoop 等大数据平台上,拥有大量非结构化数据的存储空间,非常适合数据科学家和分析师存储原始数据。有时候用户不知道自己用这些数据能做什么,但是随着持续进行数据挖掘,原始数据的存储价值逐渐凸显。
随着用户对湖和仓的要求不断提高,自然会出现湖仓协同的尝试和探索,也就形成了 MPP + Hadoop 模式,我们称之为湖仓分体模式。湖仓分体模式下的湖、仓各自独立部署,数据通过 ETL 的方式打通,但这种模式的最大问题和特点是数据孤岛。

随着公有云和私有云的普及,为了保证存储和计算可以独立的弹性扩展和伸缩,数据平台的设计出现了一个崭新的架构,即存算分离架构。MPP 数据库存算耦合,而 Hadoop 不得不通过计算和存储部署在同一物理集群拉近计算与数据的距离,因此 MPP 和 Hadoop 都不再适应云平台的要求。在此阶段,Snowflake 和 OushuDB 突破了传统 MPP 和 Hadoop 的局限性,率先实现了存算完全分离,成为湖仓一体实现的关键技术。
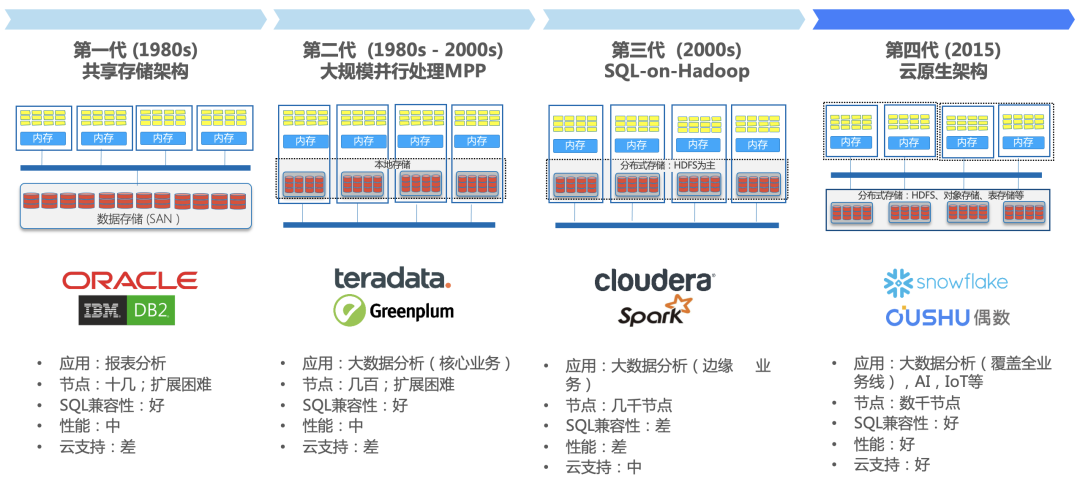
以 OushuDB 为例,实现了存算分离的云原生架构,并通过虚拟计算集群技术在数十万节点的超大规模集群上实现了高并发,保障事务支持,提供实时能力,一份数据再无数据孤岛。


