NoteBook功能
NoteBook功能#
LittleBoy NoteBook提供了一个在LittleBoy使用的python环境下编辑并运行代码的界面。通过加载littleboy库的方法,能很方便地和LittleBoy及OushuDB无缝联通。用户可以在自定义的Note中自由探索数据、自定义模型结构。可以把自定义的Keras模型保存到LittleBoy系统中进行分布式训练,而不只局限于系统给定的算法,扩展了LittleBoy模型训练的广度和深度。 NoteBook的首页用于展示所有Note的详细信息,管理系统中的Note,方便进行筛选、排序、删除等操作。
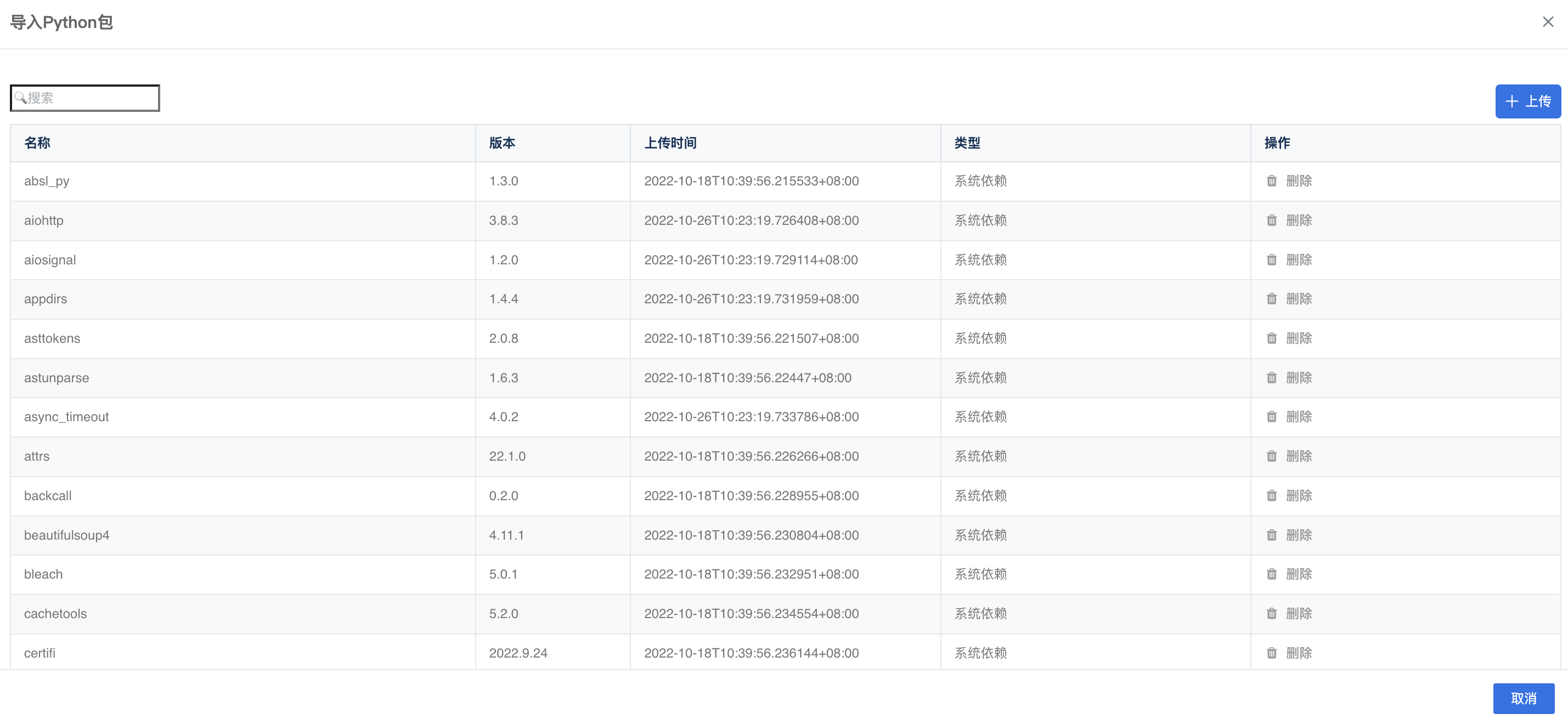
点击右上角的”导入python包“,可以查看并搜索当前python环境中已安装的库,如果需要的库不在其中,可以点击”上传“按钮导入相应的.whl包。
点击左上角的”新建Note”按钮,输入文件名称,就可以进入刚刚创建的Note的编辑界面。我们将结合 “littleboy” python库的使用,讲解notebook的具体使用。 首先导入我们需要的库函数:
import matplotlib as plt
import tensorflow as tf
import littleboy as lb
from littleboy.api.dataset import LBDataset
from littleboy.api.context import LBContext
设置好运行所需要的环境。由于需要与littleboy server进程通讯,需要设置好server的地址和认证用的token,其中token可以从Oushu Lava页面右上角点击用户名,选择用户信息,并在用户信息页面复制“token”一栏。
lb.set_lb_server("http://127.0.0.1:18080")
lb.set_token("LTEwXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
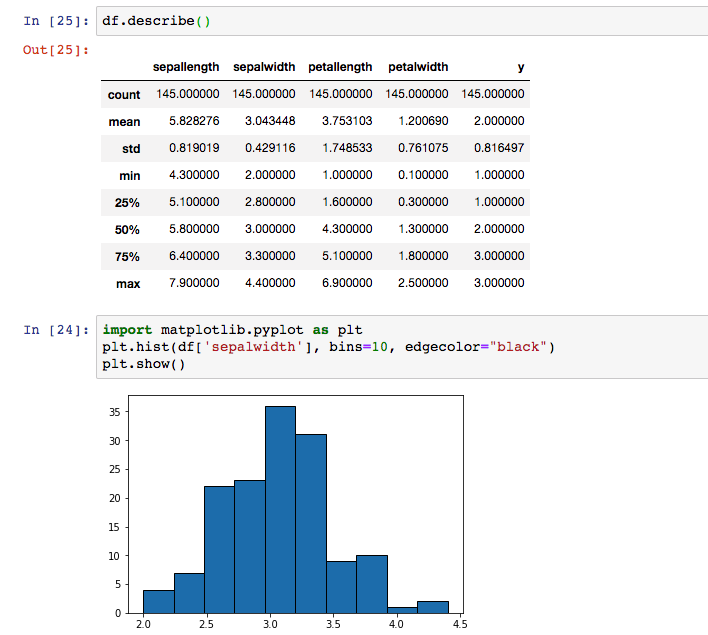
首先介绍LBDataset的使用。LBDataset可以自动连接OushuDB中的数据,并转换成方便在python环境中使用的格式。只需要在初始化LBDataset实例时传入集群名、数据库名、schema名和表名四项参数,这个dataset实例就能成为一个在目标表中迭代获取数据的迭代器,每次迭代返回表格中的一行数据,使用方法可参照Tensorflow Dataset。 使用convert_to_pandas_dataframe()函数,还可以返回一个pandas.Dataframe,更适合数据分析使用。例如,使用dataframe.describe()获取数据的描述信息,使用之前导入的matplotlib绘制直方图等。需注意的是,转换成Dataframe需要将全量数据读取到内存中,不推荐在数据量过大的表格上使用。
dataset = LBDataset("oushu-db", "postgres", "public", "iris_train")
for row in dataset:
print(row)
df = dataset.convert_to_pandas_dataframe()
df.describe()
“littleboy”库的另一项重要功能是LBContext,它允许用户在NoteBook里自定义的Keras Model作为训练模型,初始化并执行AI任务,并且在LittleBoy的分布式集群上进行训练。一个简单的实例流程如下: 首先设置littleboy server的连接地址和使用的token。设置AI任务的名称和任务描述
mytrain = LBContext()
mytrain.set_lb_server("http://127.0.0.1:18080")
mytrain.set_token("LTEwXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX")
mytrain.set_name("keras_distributed_train_example").set_desc("This is a demonstration of LBContext api")
和“AI任务”章节中新建任务的流程类似,这里也要训练使用的训练数据和评估数据,并且选定使用表格中的哪些列作为训练和预测数据。
# Set train and evaluate data
mytrain.set_train_data("oushu-db", "postgres", "public", "iris_train") \
.set_evaluate_data("oushu-db", "postgres", "public", "iris_train")
# Set feature and label
mytrain.set_features(["sepallength", "sepalwidth", "petallength", "petalwidth"]).set_label("y")
mytrain.set_model_kind("classify")
在这里我们自定义了一个单隐藏层的Keras DNN模型,并且将其作为参数传入了LBContext里。
# Set customized Keras model
layers = [Dense(32, activation="relu", input_shape=(4,)),
Dense(3, activation="softmax")]
k_model = Sequential(layers)
mytrain.set_model(k_model)
训练开始前,还需要指定分布式训练所使用的训练集群
# Set LittleBoy cluster for training
mytrain.set_trainer_cluster_name("faketrainer")
检查一切参数设置正确后,就可以通过launch()来开始训练了。
#confirm that the train configs are correct
mytrain.info()
# Start train
mytrain.launch()
一旦成功开始训练,就可以在”AI任务页面”查看正在执行的训练任务了。这之后的操作流程和之前介绍的基本相同,在此不再赘述。
附:LBContext的配置比较复制,在此列出所有的子函数:
函数名 |
说明 |
|---|---|
set_name(name: str) |
设置workflow名称 |
set_desc(desc: str) |
设置workflow描述 |
set_lb_server(addr: str) |
设置LittleBoy的server地址,默认”http://127.0.0.1:18080” |
set_token(token: str) |
设置Lava token(可在右上角用户名-用户信息-token查看) |
set_trainer_cluster_name(name: str) |
设置训练使用的训练集群(可在AI集群页面查看) |
set_train_data(cluster_name, db, schema, table: str) |
设置训练表的信息 |
set_evaluate_data(cluster_name, db, schema, table: str) |
设置评估表的信息 |
set_predict_data(cluster_name, db, schema, table: str) |
设置预测表的信息 |
set_features(features: list) |
从训练表中选择训练用feature列,用list传入 |
set_label(label: str) |
从训练表中选择训练用label列 |
set_model_kind(kind: str) |
设置模型种类,可选”classify”,”regression”,”clustering” |
set_model(model: tf.keras.Model) |
设置自定义的Keras模型 |
info() |
打印模型详情,筛选是否有遗漏的配置项 |
launch() |
保存并执行训练任务 |