数据源使用手册
本页目录
数据源使用手册#
本章将介绍如何配置不同类型的数据源
数据源列表#
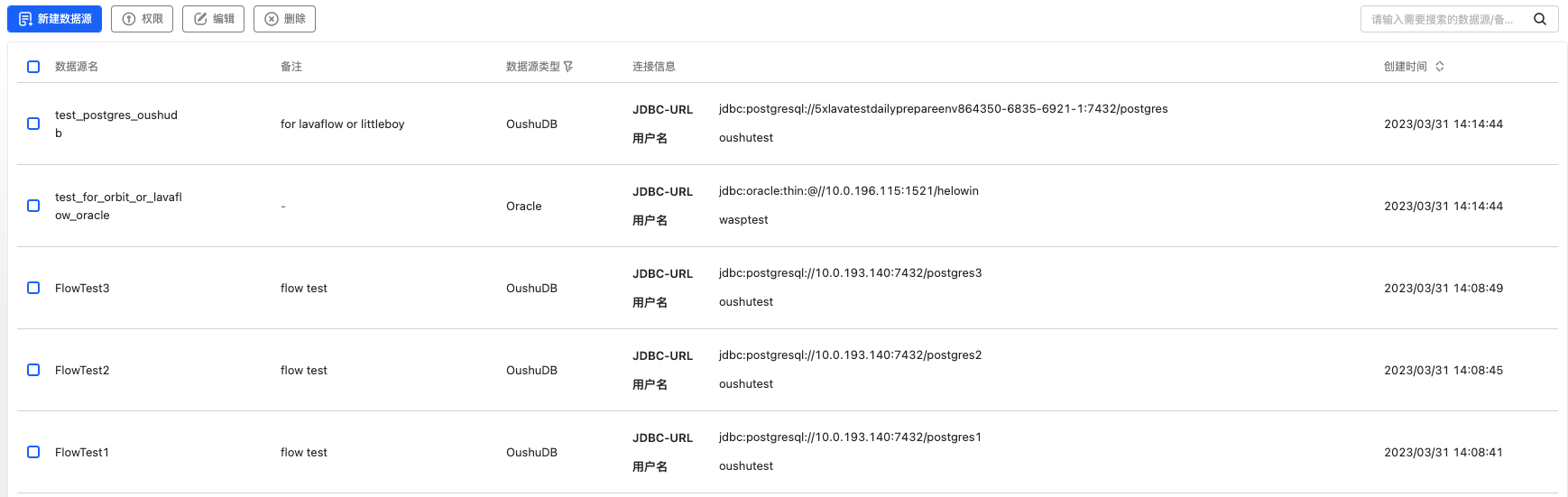
点击菜单跳转到数据源服务后,进入到了数据源列表页面。
数据源列表展示了当前数据源服务下所管理的所有数据源信息,包括不同数据源的类型,连接信息和创建时间等。
数据源默认会根据最新时间排序展示全部类型的数据源,可以通过名称或者备注查询
数据源管理#
本节将介绍对不同类型数据源的管理,包括新建、权限、编辑、删除等功能。对应操作按钮在页面左上角展示,除新建按钮常亮,其余按钮需要选中数据源后可以使用,也可将鼠标悬浮在具体某个数据源上也会有对应按钮和提示
新建数据源#
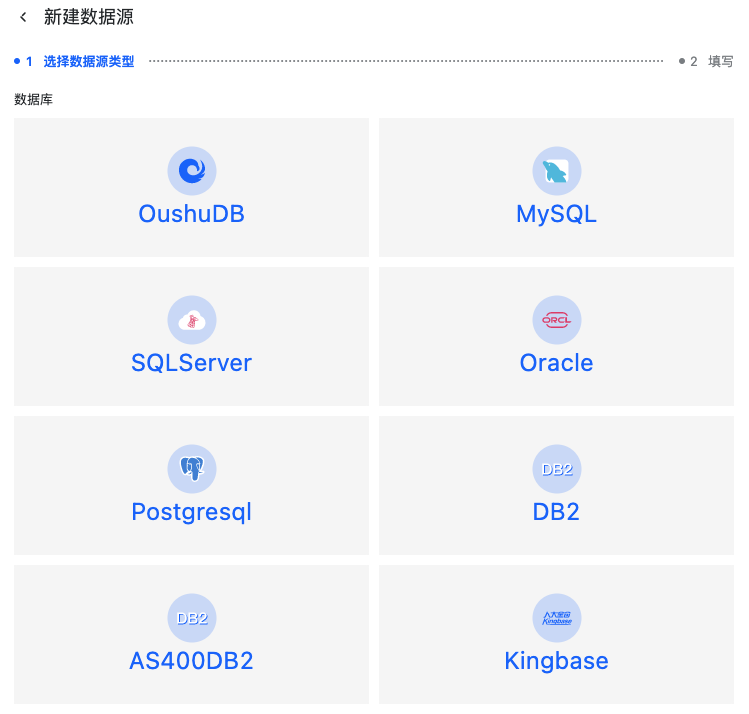
点击页面左上角“新建”数据源,进入数据源新建页面。
目前支持的数据源有三大类型:关系型数据库,文件系统,数据流。下面将分别介绍如何创建不同类型的数据源。

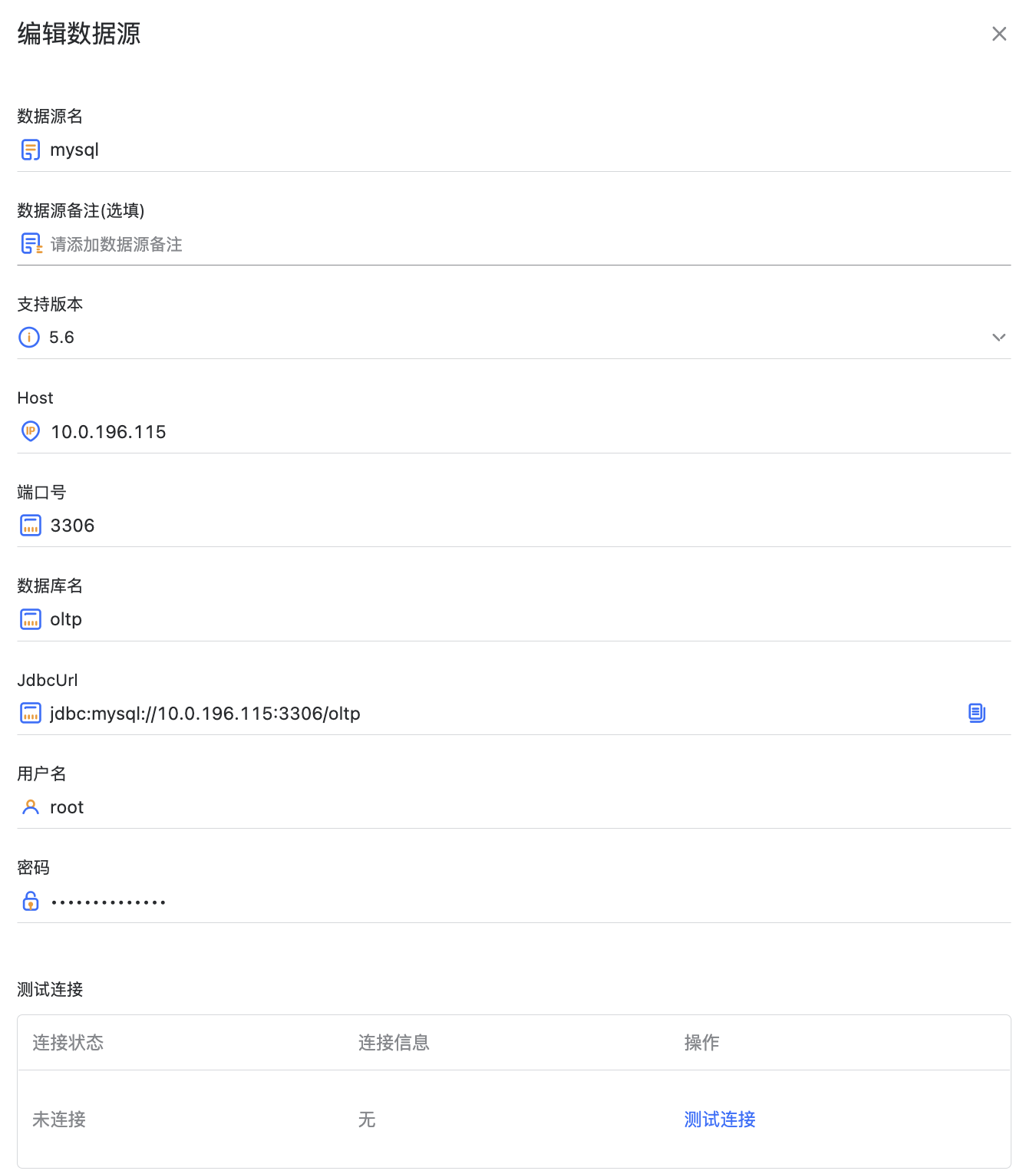
创建RDB类型的数据源#
这里以 OushuDB 举例,鼠标点击具体数据源类型后,进入了数据源信息创建页面。
在这个表单中需要填写如下的信息:
数据源名称,注意不可重名
备注(选填)
支持版本,需要确定自己所用的数据源版本是否支持
Host,当前数据源服务能够访问到的地址
端口,该数据源所占用的端口号,这里会推荐官方默认端口号
数据库名,该数据源连接指向哪一个数据库
JdbcUrl,JDBC 连接串会根据上面输入的 Host,端口号,数据库名辅助生成,也可根据自己数据源配置进行手动调整
用户名,具有正常访问权限的用户
密码,该用户的对应密码
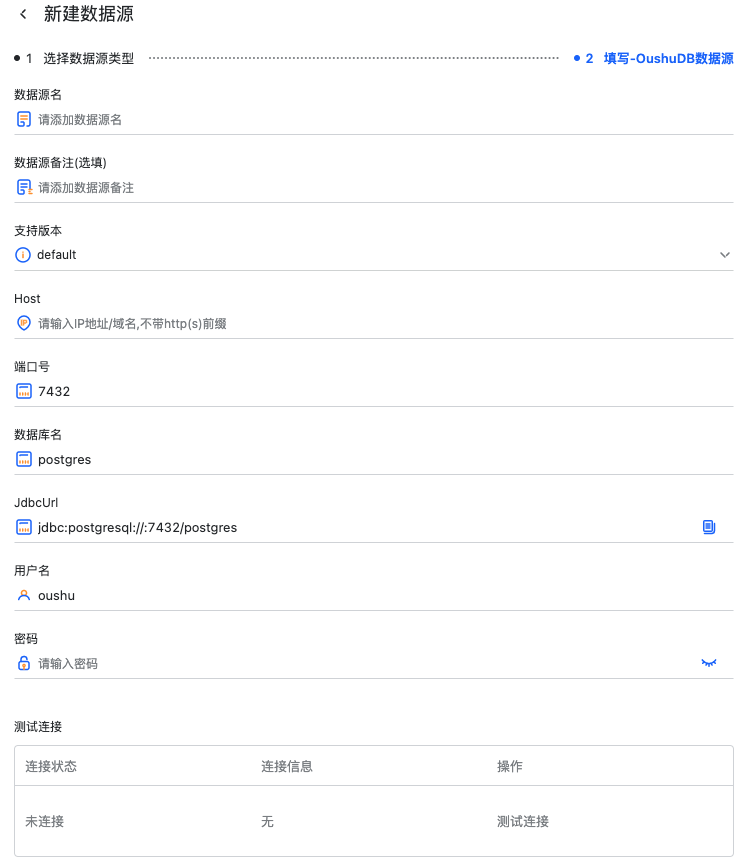

数据源信息填写完成后,可以点击测试连接判断数据源是否连通。
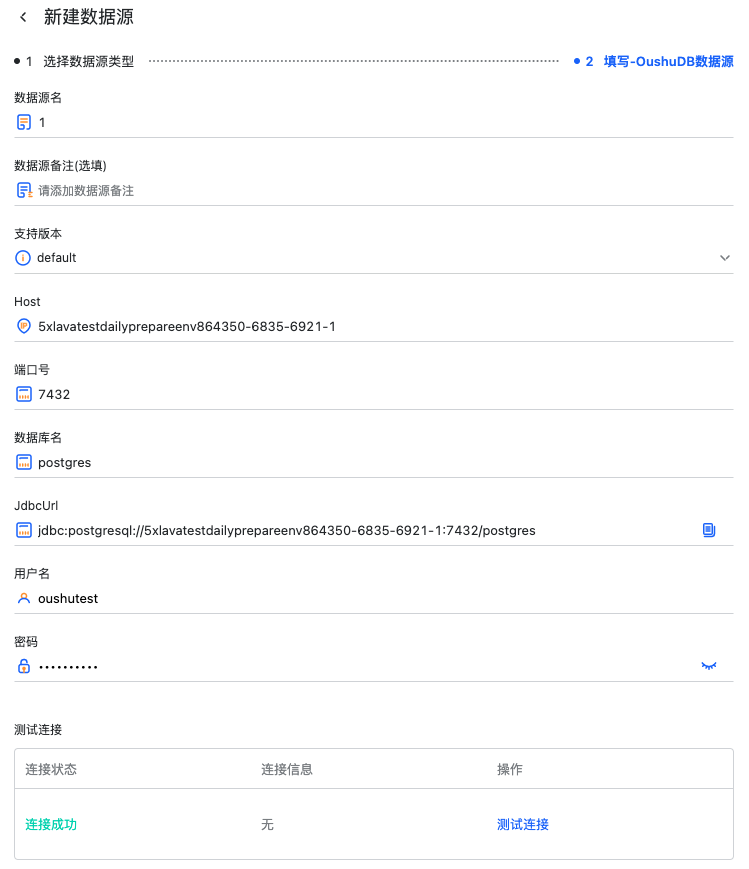
如果连接失败,鼠标悬浮在连接信息的内容时,会有具体的失败提示。

此时点击创建数据源即创建成功,并回到数据源列表页面。
创建文件类型的数据源#
这里以 HDFS 举例,HDFS 有 HA 开关来控制该 HDFS 数据源是否是 HA 的。
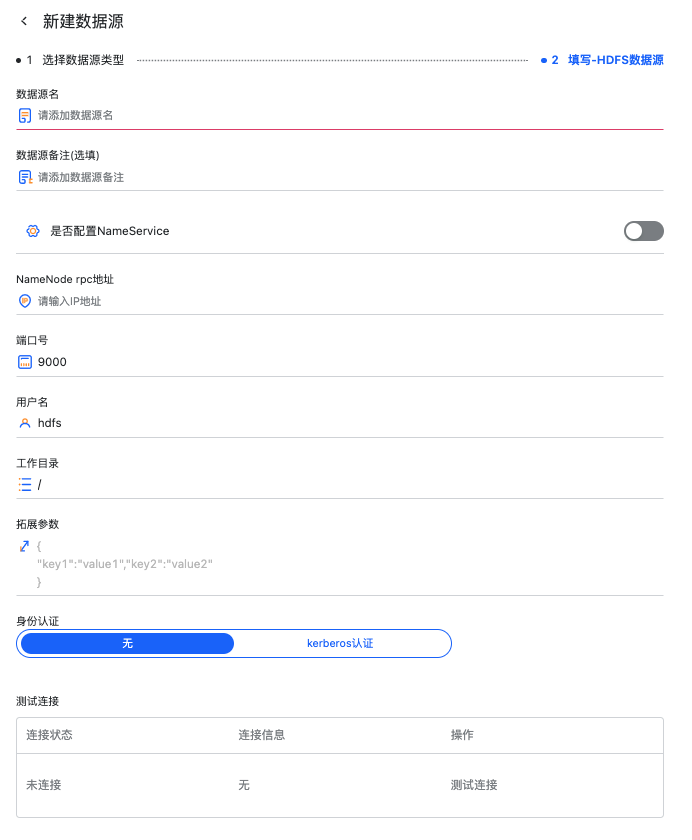
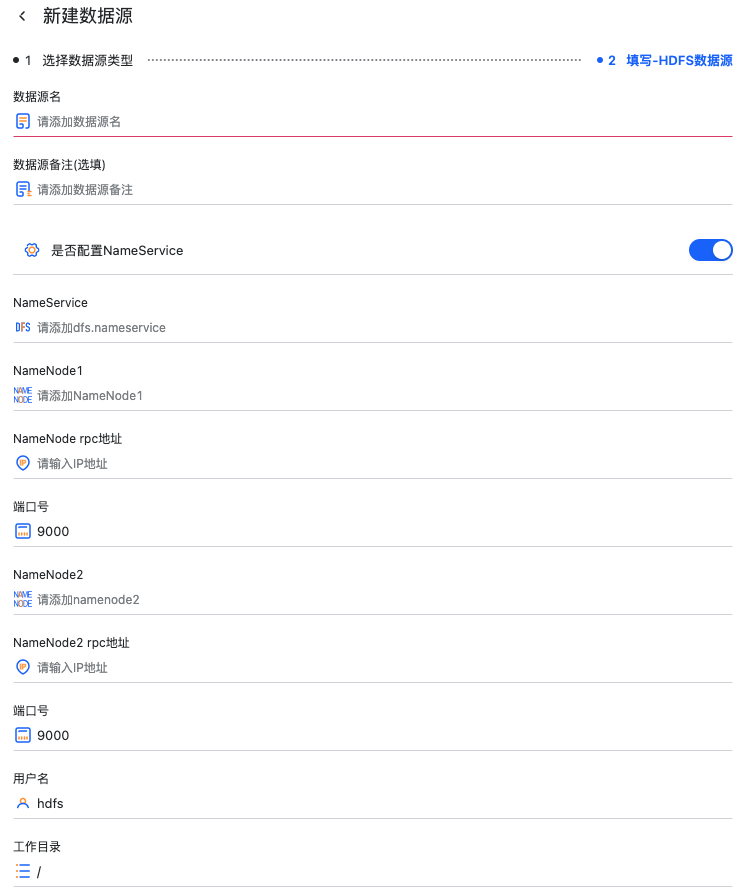
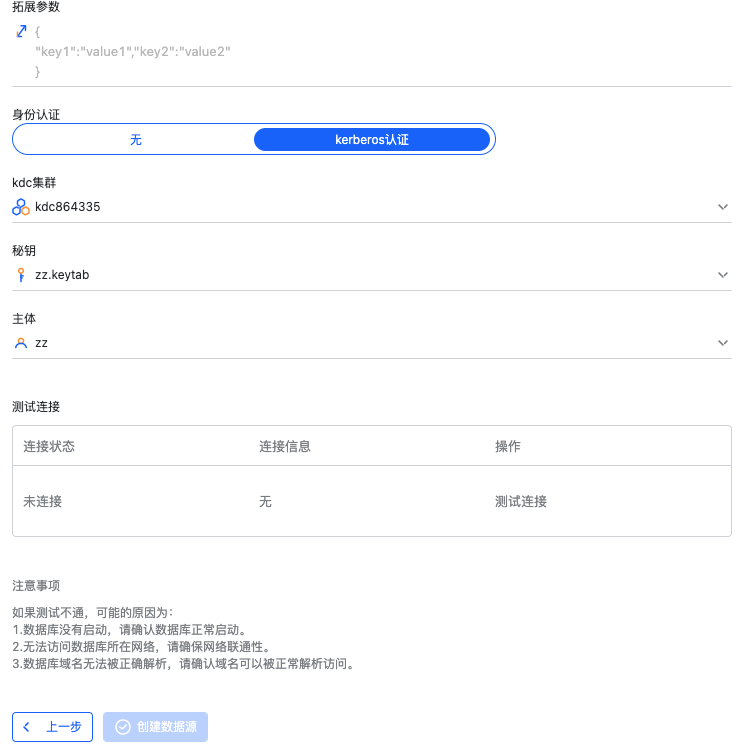
有如下数据源连接信息需要填写
数据源名称
数据源备注
连接信息
非 HA 模式
HDFS 的 NameNode rpc 地址
NameNode 端口号
HA 模式
HA 模式下的 dfs.nameservice
NN1 的 IP 和端口
NN2 的 IP 和端口
连接的用户
工作目录
拓展参数
身份认证
无:服务未集成第三方身份认证
Kerberos 认证:
选择需要认证的 KDC 集群
选择认证使用的 Keytab 文件
选择对应的 Principal
创建流类型的数据源#
这里以 Kafka 数据源举例,需要填写这些数据源信息:
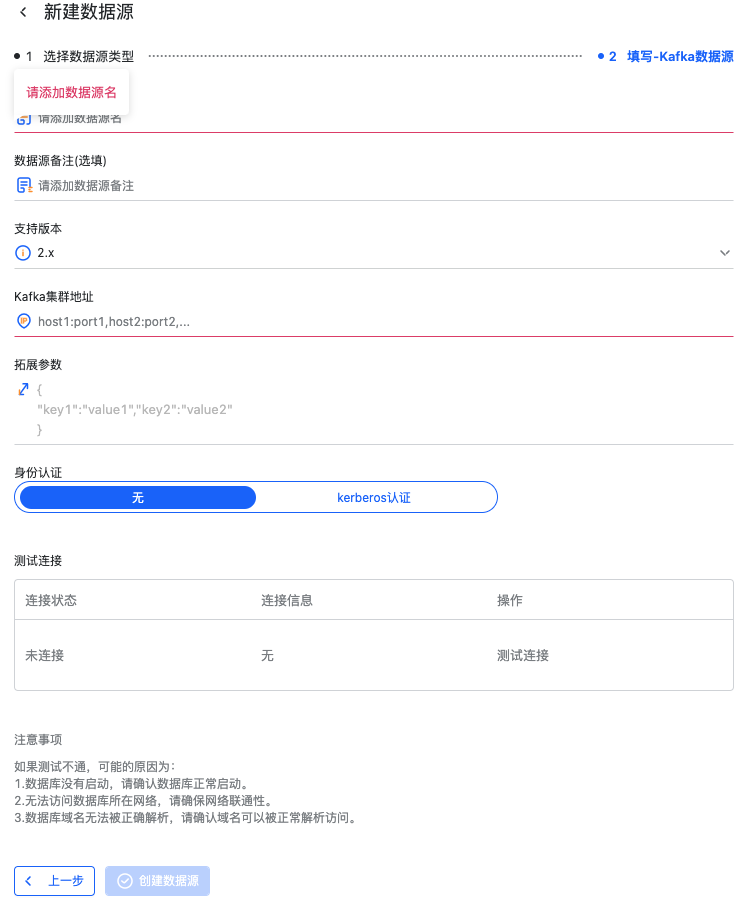
需要填写这些数据源信息
数据源名称
数据源备注
支持的 Kafka 版本
Kafka Broker 集群地址
Consumer 拓展参数(选填),以 JSON 类型格式填写。
身份认证
无:服务未集成第三方身份认证
Kerberos 认证:
选择需要认证的 KDC 集群
选择认证使用的 Keytab 文件
选择对应的 Principal
数据源权限#
数据源权限的赋予方式有两种,可以通过“个人中心”->“用户管理”进行全局通用的权限管理,另一种则是在数据源列表处选中具体某个数据源后,对该数据源的对象权限进行设置。
个人中心权限#
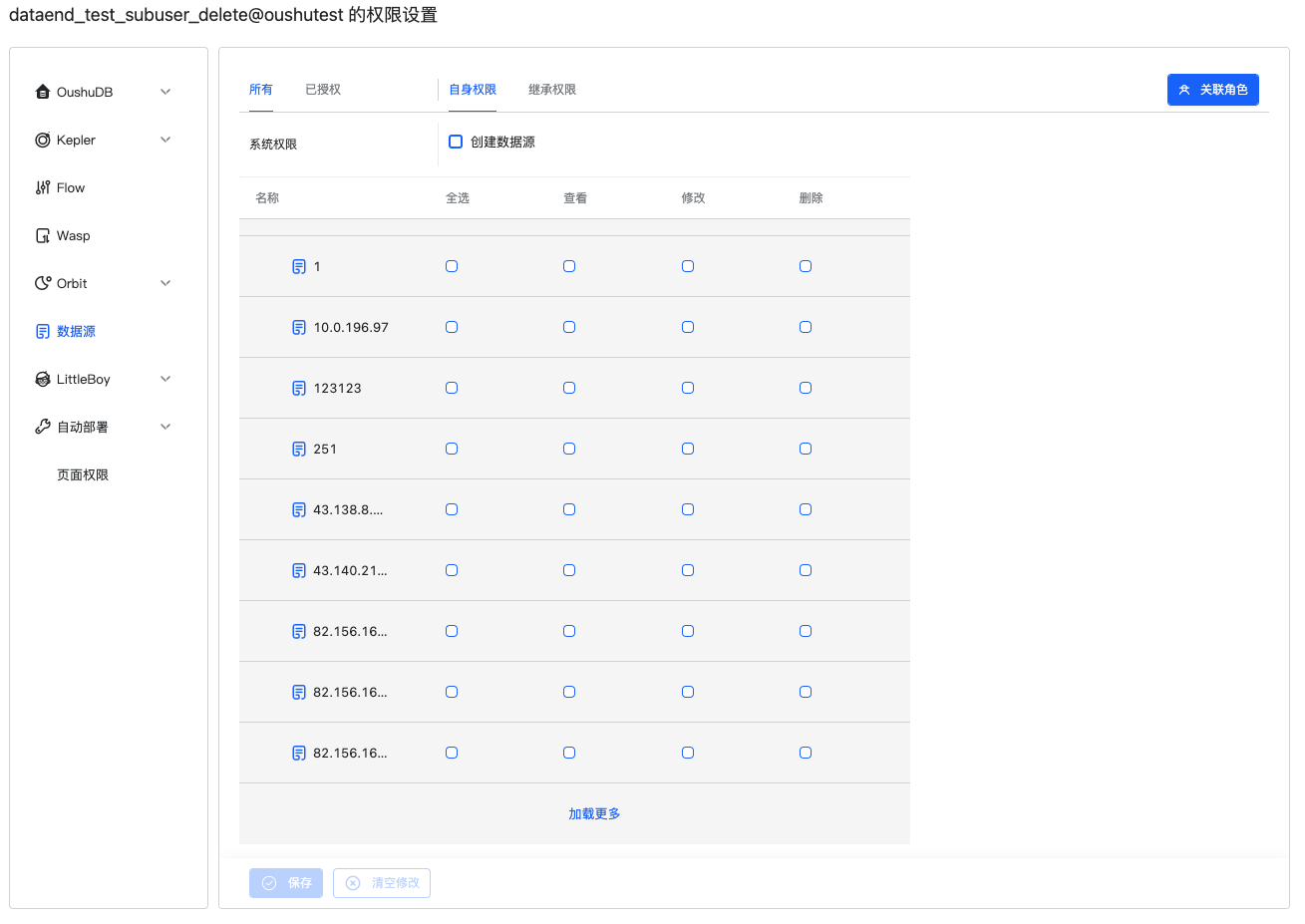
个人中心的权限设置包括对所有数据源的权限设置,同时创建数据源的权限只能在这里赋予给用户和角色
数据源对象权限设置#
数据源对象的权限设置只能对单一数据源进行赋权,且不具备给用户赋予创建数据源的权利
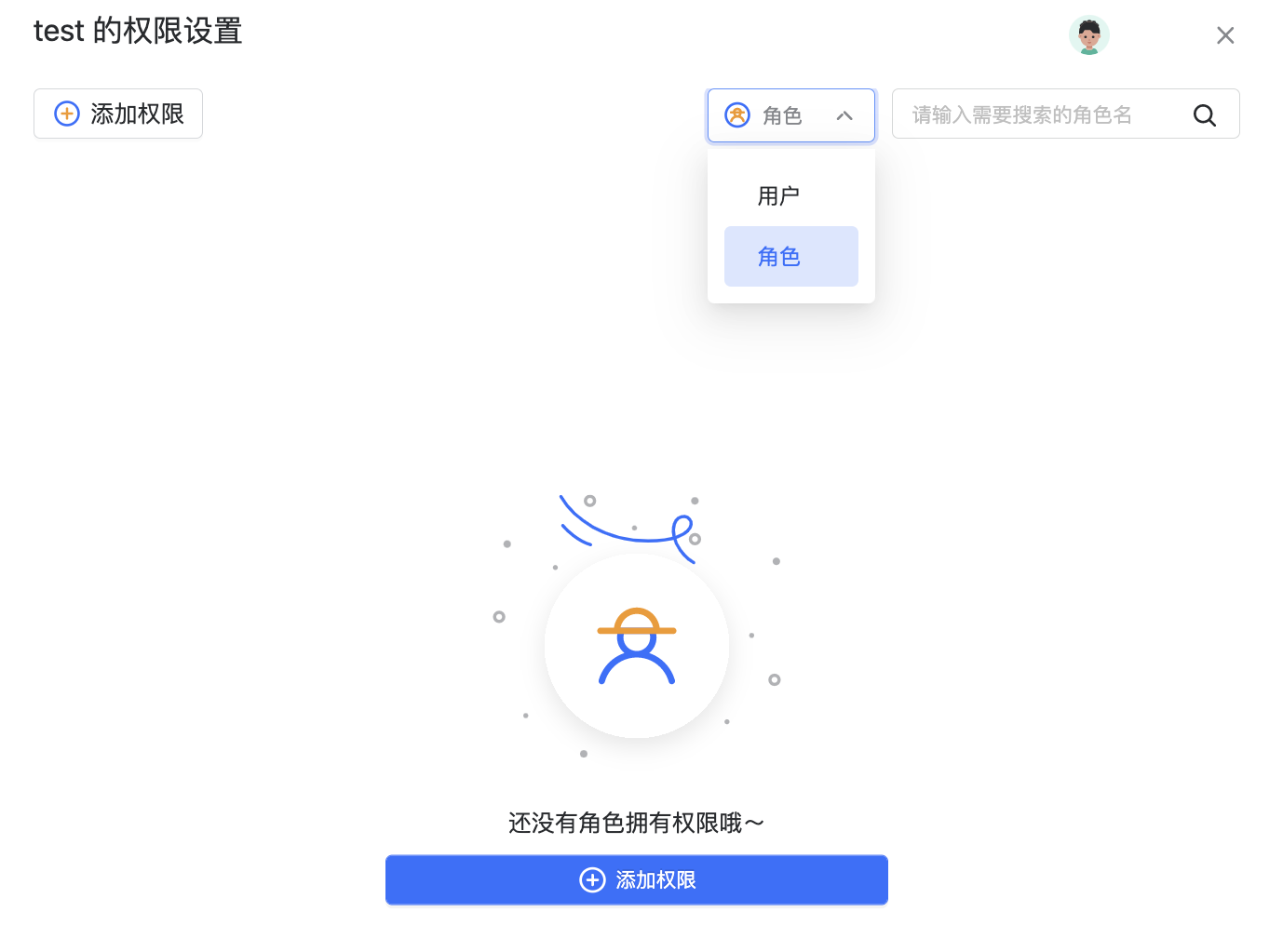
选中数据源点击权限后,可以进入到数据源权限的页面,在右上角可以切换显示已经具有权限的角色或子用户。
点击“添加权限”,可以给角色和子用户赋权。
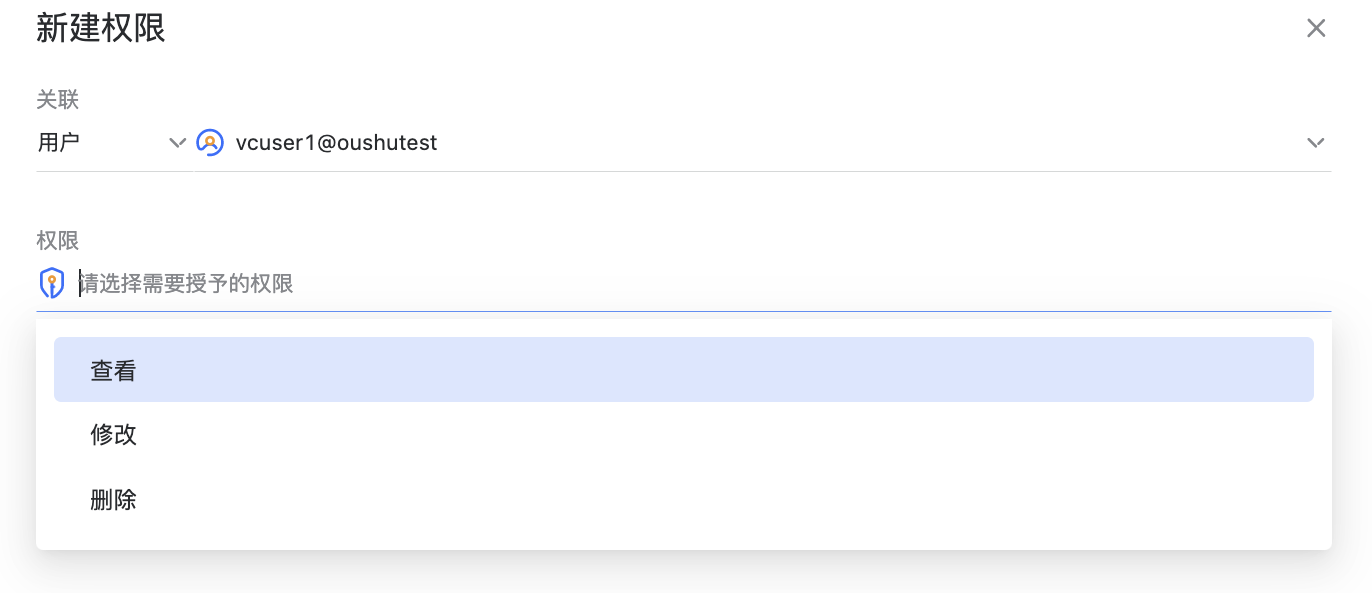
数据源的对象权限管理分为三种:
查看,允许该用户或角色查看数据源信息
修改,允许该用户或角色修改数据源信息
删除,允许该用户或角色删除该数据源
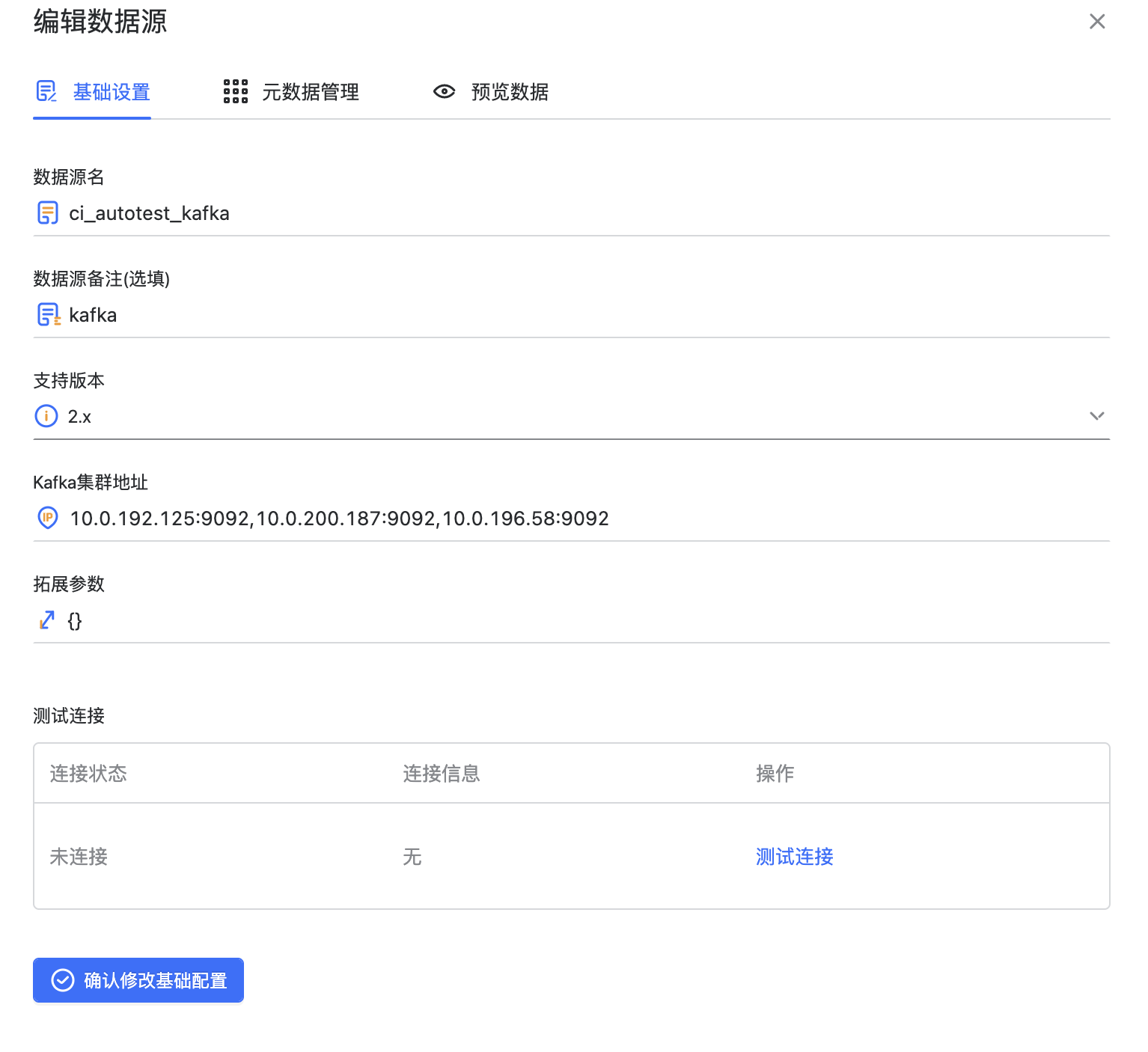
编辑数据源#
点击编辑按钮可以进入数据源的编辑界面,和创建数据源的界面相似,可以修改数据源信息和测试连接
这里有区别的是 Kafka 类型的数据源,除了基础的集群连接信息外,还包括元数据管理和预览数据。元数据的管理详见下一节,这里介绍预览数据
点击预览数据后可以看到 Kafka 集群的信息,包括集群里的 Topic。
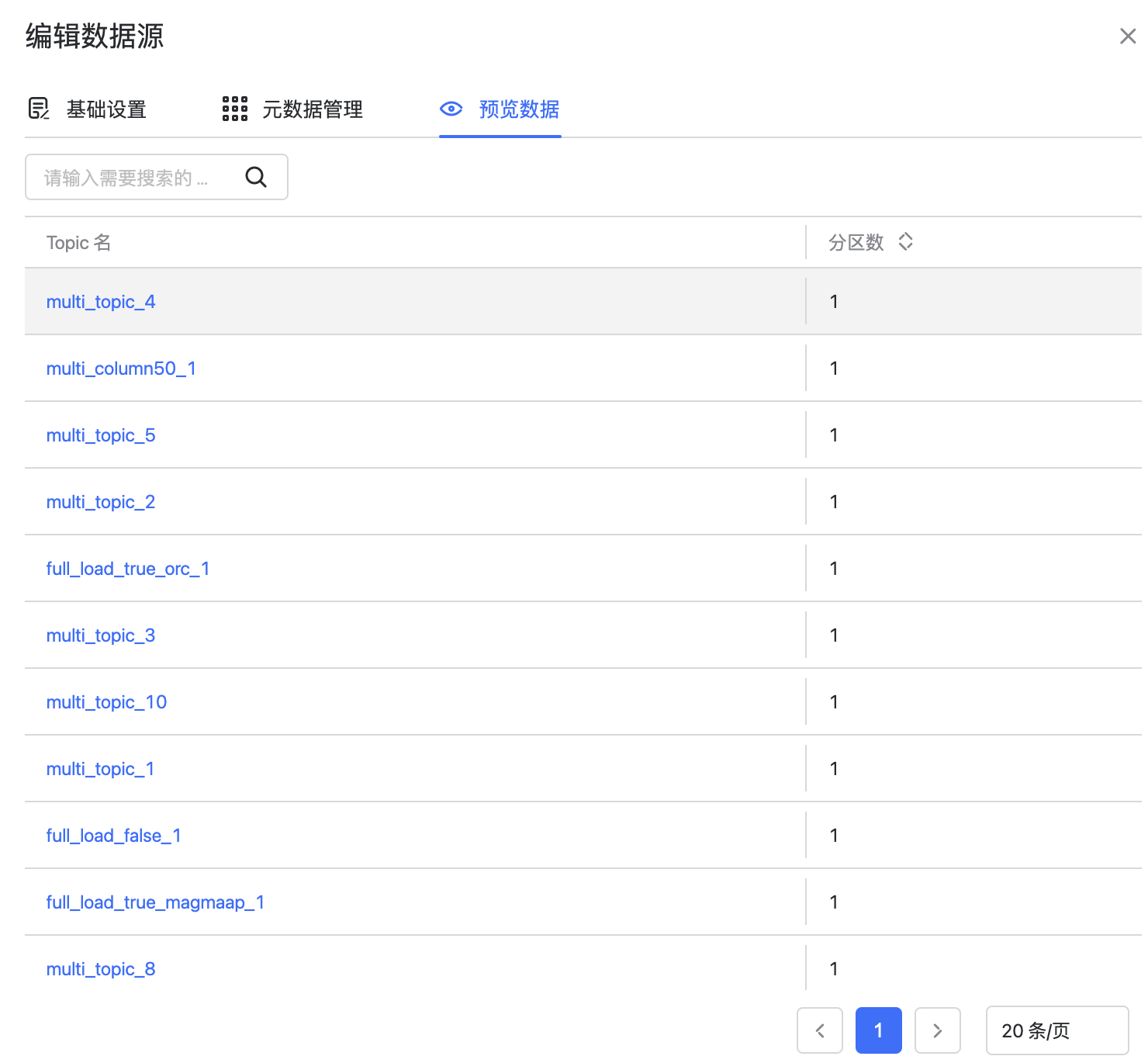
点击对应 Topic 后可以看到 Topic 的所有分区信息,包括分区号,Leader,副本,ISR,数据总量。
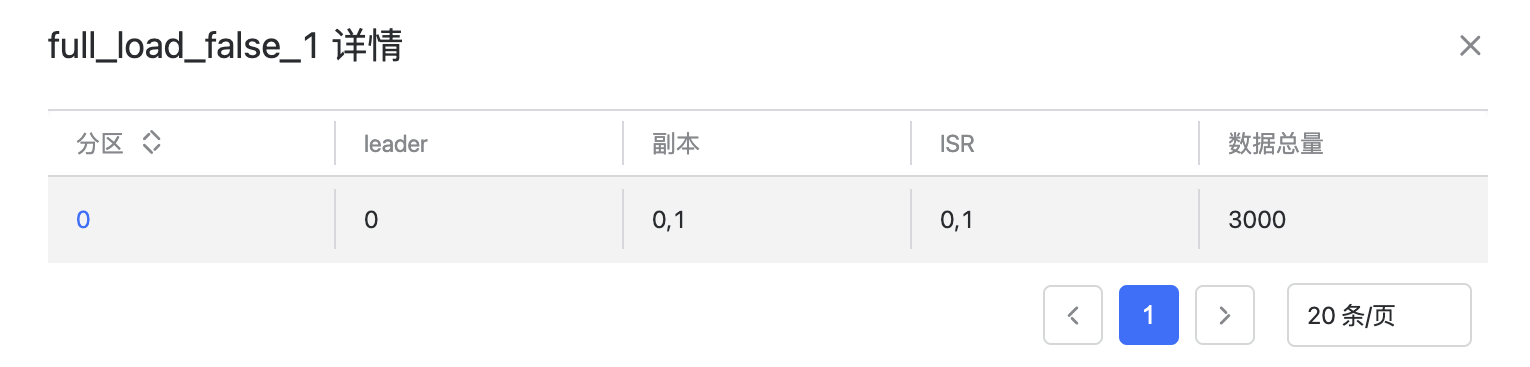
点击数据总量>0的具体分区,可以预览该分区的数据,会显示数据的偏移量,key,value 和时间戳,这里最多可以预览10条数据。

删除数据源#
数据源悬浮按钮可以对单个数据源进行删除,多选数据源后也可以进行批量删除操作
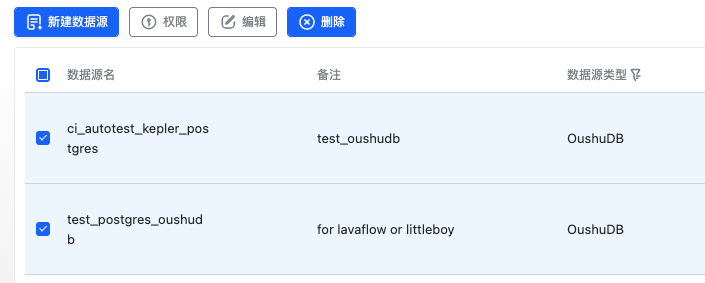
需要注意的是,数据源可能正同时被其他应用所使用,如对话式数据分析 Kepler、数据工厂 Wasp 和作业调度 Flow 等,删除需谨慎操作。
元数据管理#
元数据管理通过 Kafka,编辑数据源的入口进入。元数据目前在 Wasp 数据工厂中使用,支持将 CSV 和 JSON 类型的数据转换为数据库表中的数据。元数据的定义即这些数据的库表结构。
元数据管理列表展示了元数据的基础信息,包括元数据名称,类型,备注,创建时间和操作。在左上角可以新建元数据,在每个元数据的操作里可以对该元数据进行删除操作。

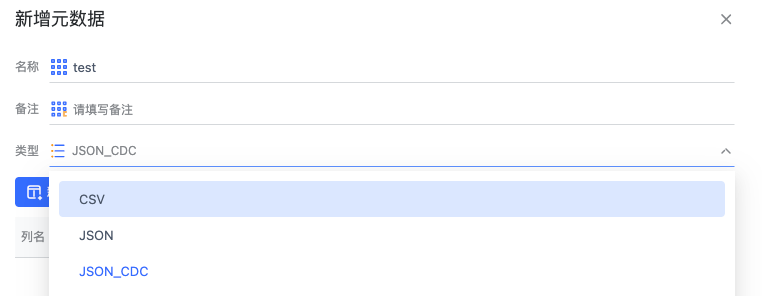
点击新建元数据,可以创建不同类型的元数据
元数据名称,最好是填写表的全限定表名,在创建 wasp 任务时更方便使用。
备注(选填)
选择元数据的类型,目前支持 JSON 和 CSV。
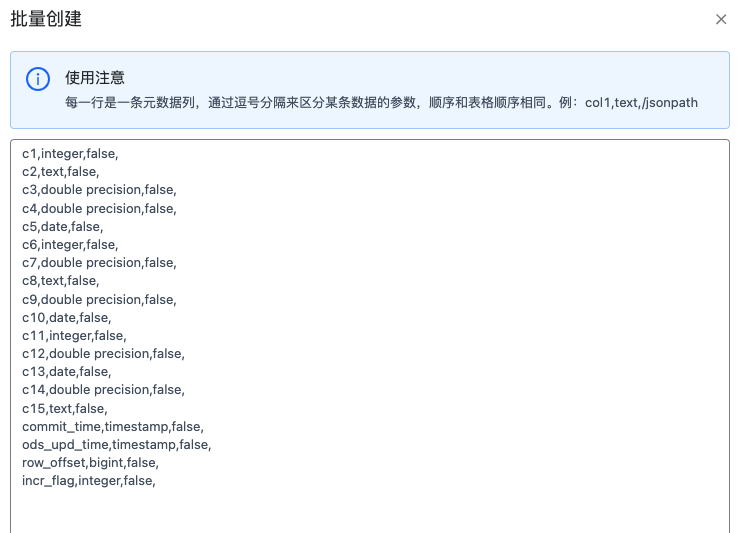
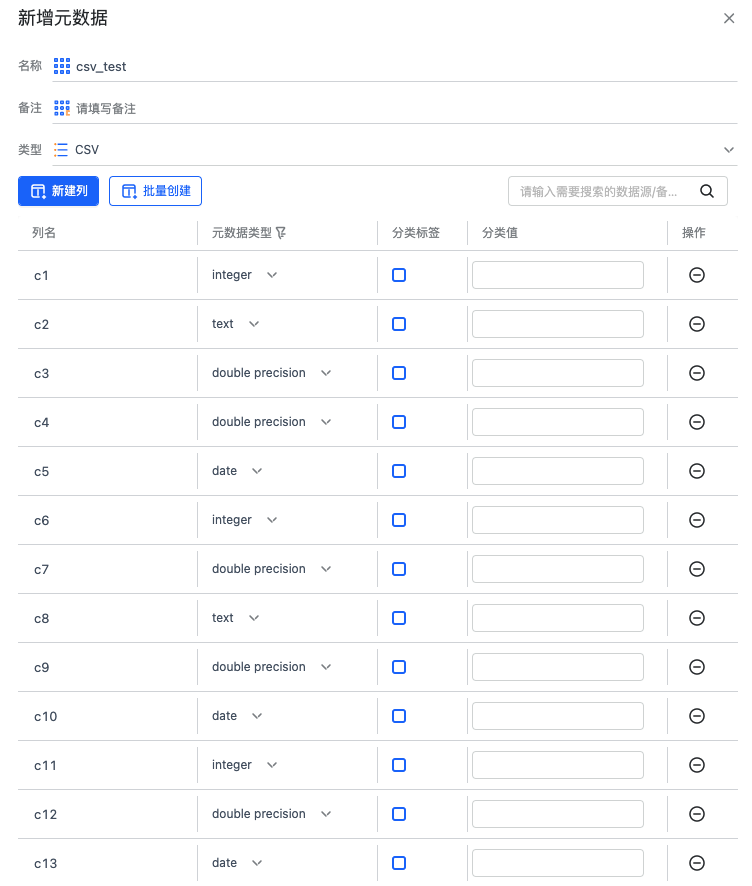
点击新建列可以创建元数据的列信息,目前元数据列类型支持7种数据类型,分别是 text,integer,double precision,bigint,numeric,date,timestamp。
CSV类型元数据#
CSV 类型元数据有分类标签和分类值,分类标签是复选选项,用来描述数据是否属于该元数据。
举例说明:
创建的元数据列分别为c1、c2、c3
有两条csv数据:
数据1: [a|b|c]
数据2: [a|b|d]
如果不设置分类标签,这两条数据都属于该元数据。如果设置 c3 为分类标签,且分类值为 ‘c’,那么只有数据1属于该元数据,数据2并不属于该元数据。
JSON类型元数据#

JSON元数据中的分类标签表示解析JSON数据时,该字段一定会在JSON数据中出现,若解析出的数据获取不到该字段值,则会判定此条数据不属于当前元数据。
JSON 类型的元数据特有的属性是 JsonPath,每个列都需要配置,是用来描述数据如何从 JSON 格式中取出。
举例说明:
{
"data": {
"a": {
"a1": "hello"
},
"b": "world"
},
"code": 1000,
"array": [
{
"value": "foo"
},
{
"value": "bar"
}
]
}
如果同步 a1 的数据 "hello",JsonPath: "/data/a/a1"
如果同步 b 的数据 "world",JsonPath: "/data/b"
如果同步 code 的数据 1000,JsonPath: "/code"
如果同步数组 array 的索引为 0 的对象中 value 字段的数据 "foo",JsonPath: "/array/0/value"
如果同步数组 array 内所有数据,并拆成多条数据,JsonPath: "/array/[*]/value"
批量创建元数据列#
可以通过文本框编辑每一行的元数据列信息,来实现元数据的快速创建。